Description:
In pursuit evasion games, each pursuer attempts to decrease the distance between evader and itself and capture the evader in minimum time, whereas the evader tries to increase the distance to escape from being captured. This project deals with evader and pursuer of equal speeds. Reinforcement learning algorithms, which involves an agent’s interaction with the environment to learn, are adopted to find a strategy for the evader to resist capture.
Framework:
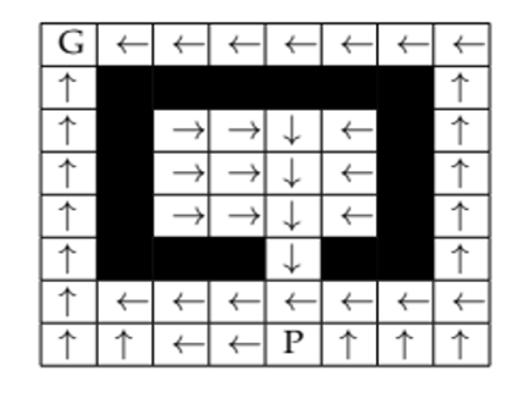
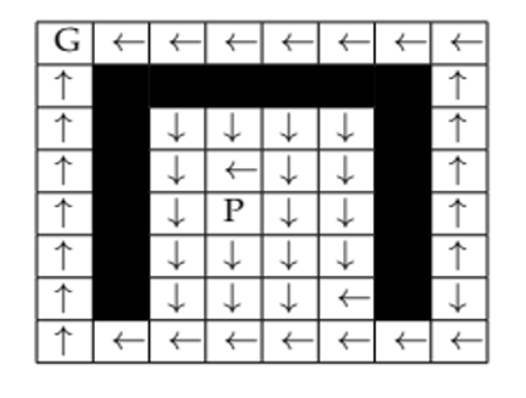
The experiments were performed on grid based environment of size 8x8 with
one pursuer and one evader. The grid has free cells, obstacles and goal. The
pursuer is equipped to follow the evader using an algorithm named A-star. The
evader uses Q-learning with artificial neural network to either reach the goal
or to keep resisting capture.
At each state except the terminal state, the
agent can move in four directions – up, right, left and down. Diagonal moves
are not possible. The world is not toroidal and hence the agent can’t fall off one
edge and emerge from the opposite end. If the agent is trying an action that
leads the agent to bump against an obstacle or an edge, the agent remains in the
same position. At the terminal state, which is the goal, the agent has no actions
and the game terminates.
Results:
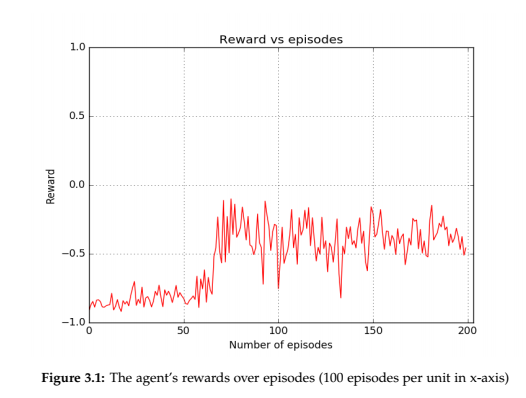
Q-Learning coupled with a neural network was used for planning a path which is a
pursuit-evasion game with no pursuers and the evader moving from the inital node
to the terminal node. The success rate was 100%.
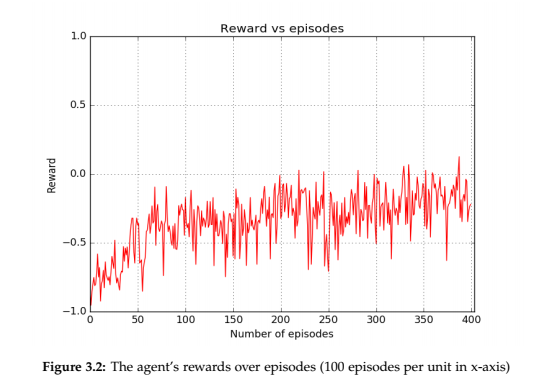
Simulation of pursuit-evasion game in a grid witout obstacles had a success rate of
92.4% for the evader. With obstacles, the success rate was 86.5% for the evader.